How to Build a Self-Describing Model Execution Platform
In highly regulated environments like banking and insurance, the demand for explainability, auditability, and replicability doesn’t stop at model development. It extends all the way through deployment, execution, and reporting. This is where most platforms fall short.
With trac, we’ve built model orchestration platform that is self-describing by design, so every calculation is explainable, auditable, and repeatable and there is no need to manual produce documentation.
Structured Metadata
At the heart of trac is the metadata model that defines and connects every object on the platform. Each of the platforms primary object types have their own metadata structure. Let’s briefly define those objects:
Model: A discrete unit of code stored in a code repository that can be used in calculations
Data: Files and records that have been made available to the platform
Flow: The blueprint of a complex calculation that TRAC can run using multiple models - the equivalent of a ‘deployment’ in traditional systems
Job: A single calculation that has been run on the platform
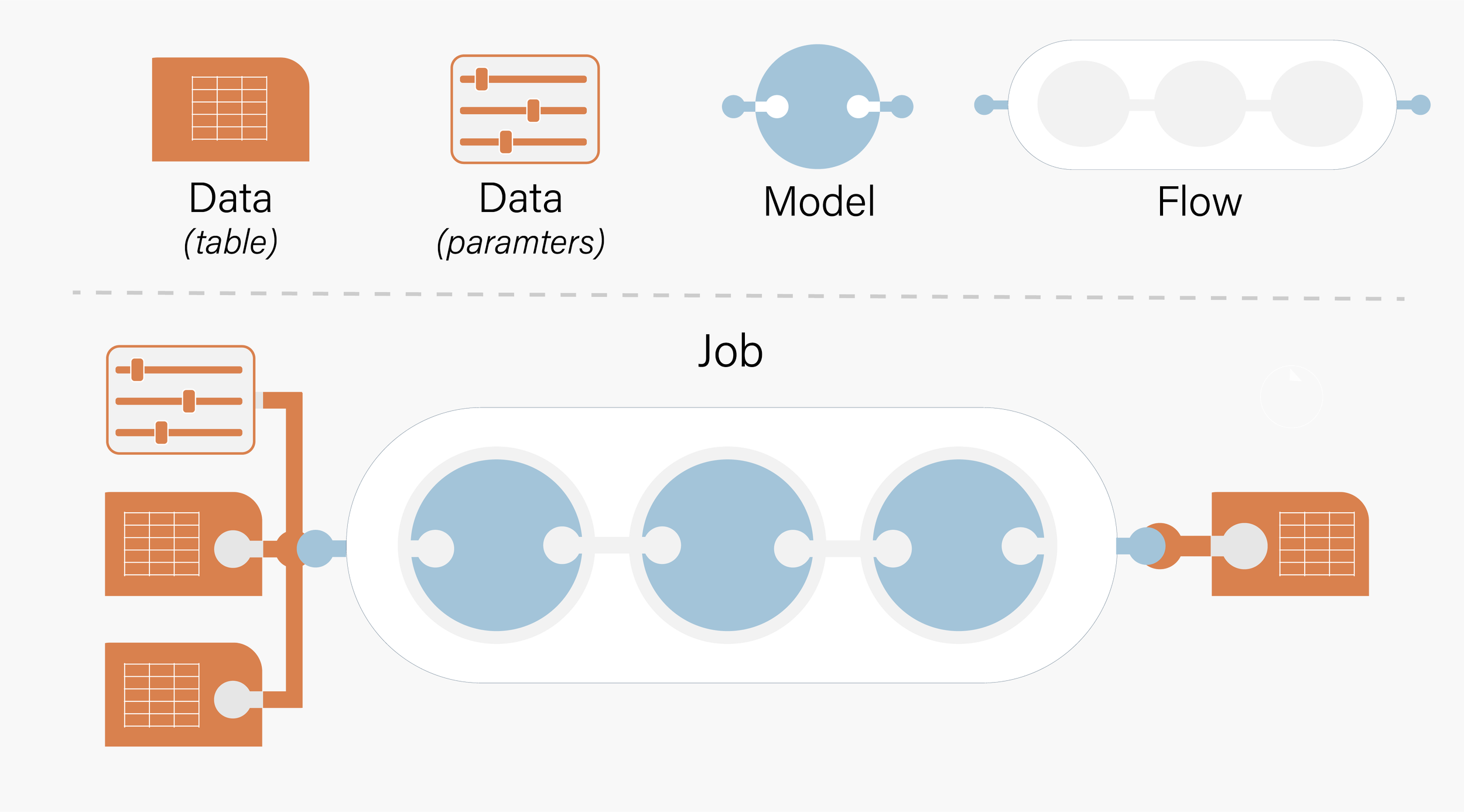
Data, Models, Flows and Jobs
Schemas, Schemas, Schemas
The metadata model includes a schema representation of every object, which fully captures its unique structure.
🔹 Data Schema: The standard - columns, fields, types, units, and constraints.
🔹 Model Schema: The set of schemas that fully describe a model’s inputs, outputs and parameters. A model schema doesn't describe its rationale or business meaning - just that if you present inputs X and Y the model generates output Z.
🔹 Flow Schema: Describes how a set of models can be connected into an execution graph. It shows:
The dependency structure between the models, where the outputs of one become the inputs to the next
The schemas of all the inputs, outputs, and parameters of the flow in aggregate
🔹 Job Schema: Provides a complete description of a calculation. This includes:
The schema of the flow that was used
Details of which data inputs and model versions were used
The parameter values defined provided via the UI when launching the job
Details of the outputs that were generated by the job
Putting the Self in Self-describing
The idea of using schemas to describe structured objects isn't particularly new. The important thing is that users only have to define these schemas for the foundational objects - models and data. As you build flows and run jobs, TRAC builds and maintains the schema representation of these objects for you.
There’s no need to manually document your deployment, or to retroactively attest to which parameter values, code versions, or input data was used in a calculation. TRAC takes care of that for you. This is what we mean by a self-describing system.
Why It Matters
Self-describing systems like TRAC do more than reduce the cost and effort of documentation - although that alone is valuable. They also:
Shorten deployment timelines
Simplify oversight and assurance activities
Remove system fragility and enable new types of self-service operating model