TRAC ECOSYSTEM
Deploy trac onto your existing data and compute infrastructure and it integrates with code repositories and development tools to create a unified ecosystem in which to build, deploy and use models.
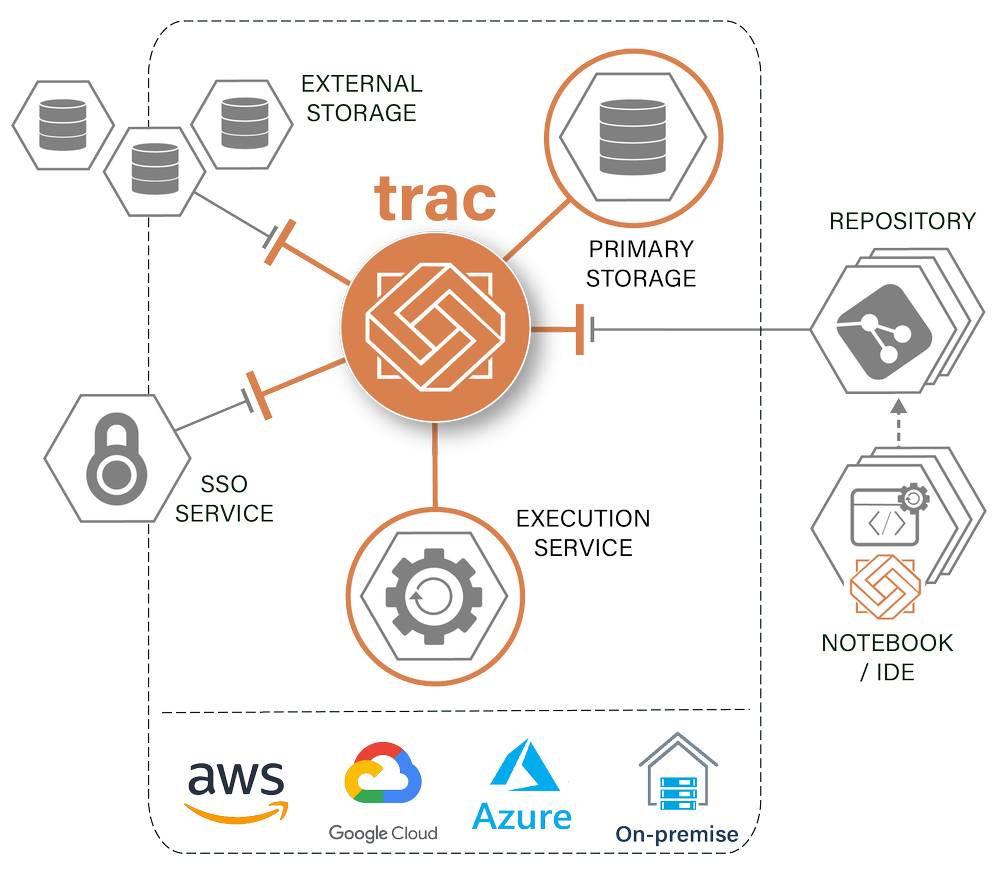
PRIMARY STORAGE
An append only data model is used to ensure job repeatability. Primary storage must therefore be a location in your data storage platform that only trac has write-access to. For cloud deployments this would be regular bucket storage. For on-premises deployments, file-based storage.
EXECUTION SERVICE
An external compute service to execute jobs. For cloud deployments, we provide a Kubernetes pattern which can support both single-node and distributed (Spark) capabilities. Integrations with Hadoop and other compute services are available for on-premises deployments.
AUTHENTICATION
Plug into your enterprise-wide SSO mechanism for watertight identity and access management, with roles assigned in the AD and fine-grain permissions being configured in trac. Azure AD, SAML and OpenID are supported out of the box, other solutions can be accomodated using plug-ins.
REPOSITORIES
Models are stored in an external repository, with the code being accessed dynamically at runtime. Integratations with GitHub, GitLab and Nexus are available as standard, custom repositories can also be accommodated using plug-ins.
NOTEBOOK / IDEs
Deploy the trac runtime library to your IDE or notebook to enjoy the type safety of production during the development process and build models which can be deployed to production with a single click and no code modification.
EXTERNAL STORAGE
Connecting to other data locations allows trac to manage the batch importing and exporting of data. Connectivity is available for several common technologies including; object storage, file-like locations, databases, and SQL-like locations. .