Simple, Secure Model Deployment
Deploy models into production processes with a few clicks and no code modification using trac's virtual deployment framework
BOOK A DEMO
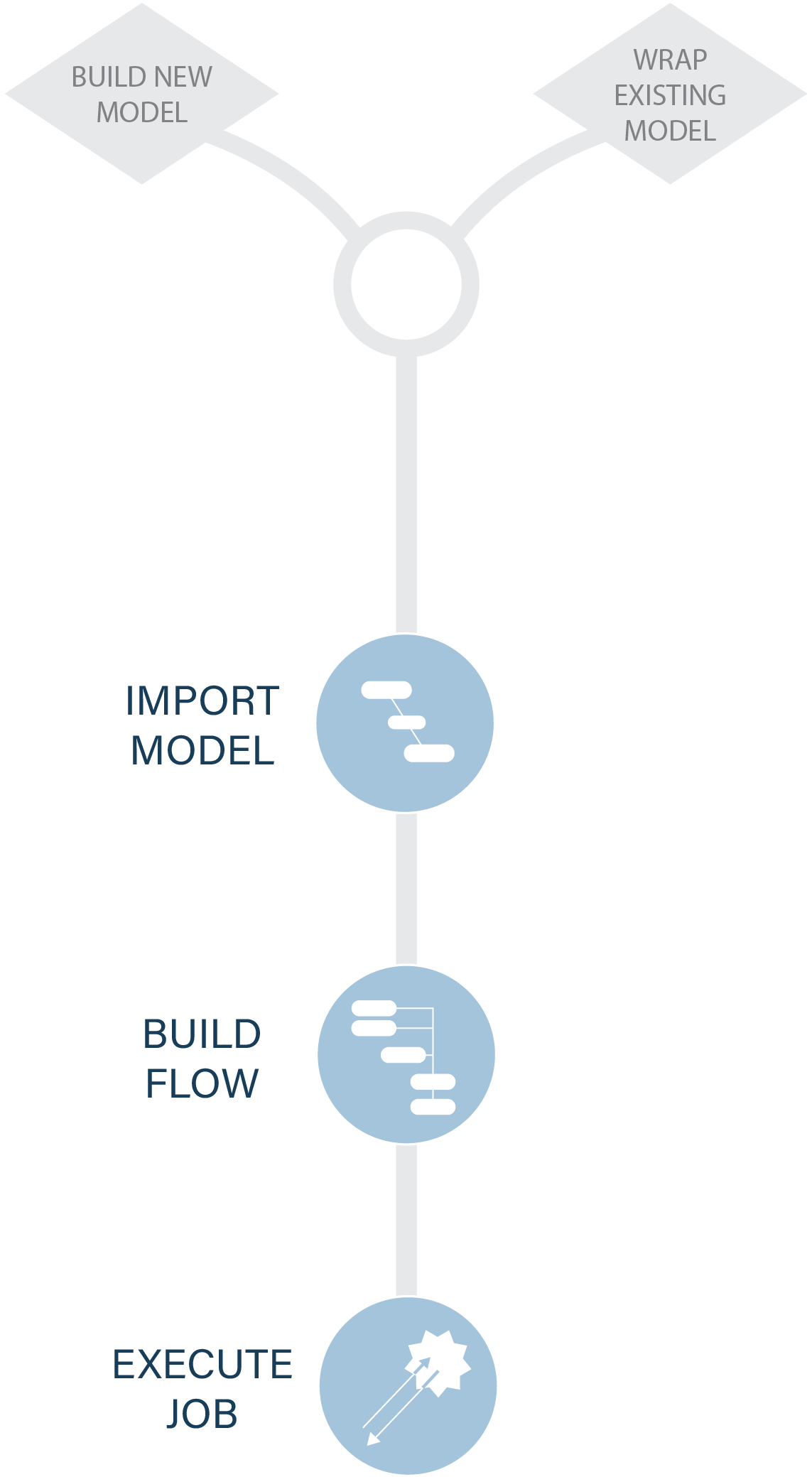
VIRTUAL DEPLOYMENT FRAMEWORK
Models are uploaded via a simple no-code process and ‘virtually deployed’ into calculation processes called Flows — the code stays in your repository until needed for a calculation.
1. IMPORT DATA
Data can be imported via the UI or using a back-end process. The import creates both the physical records in trac's primary storage and the metadata representation of the data.
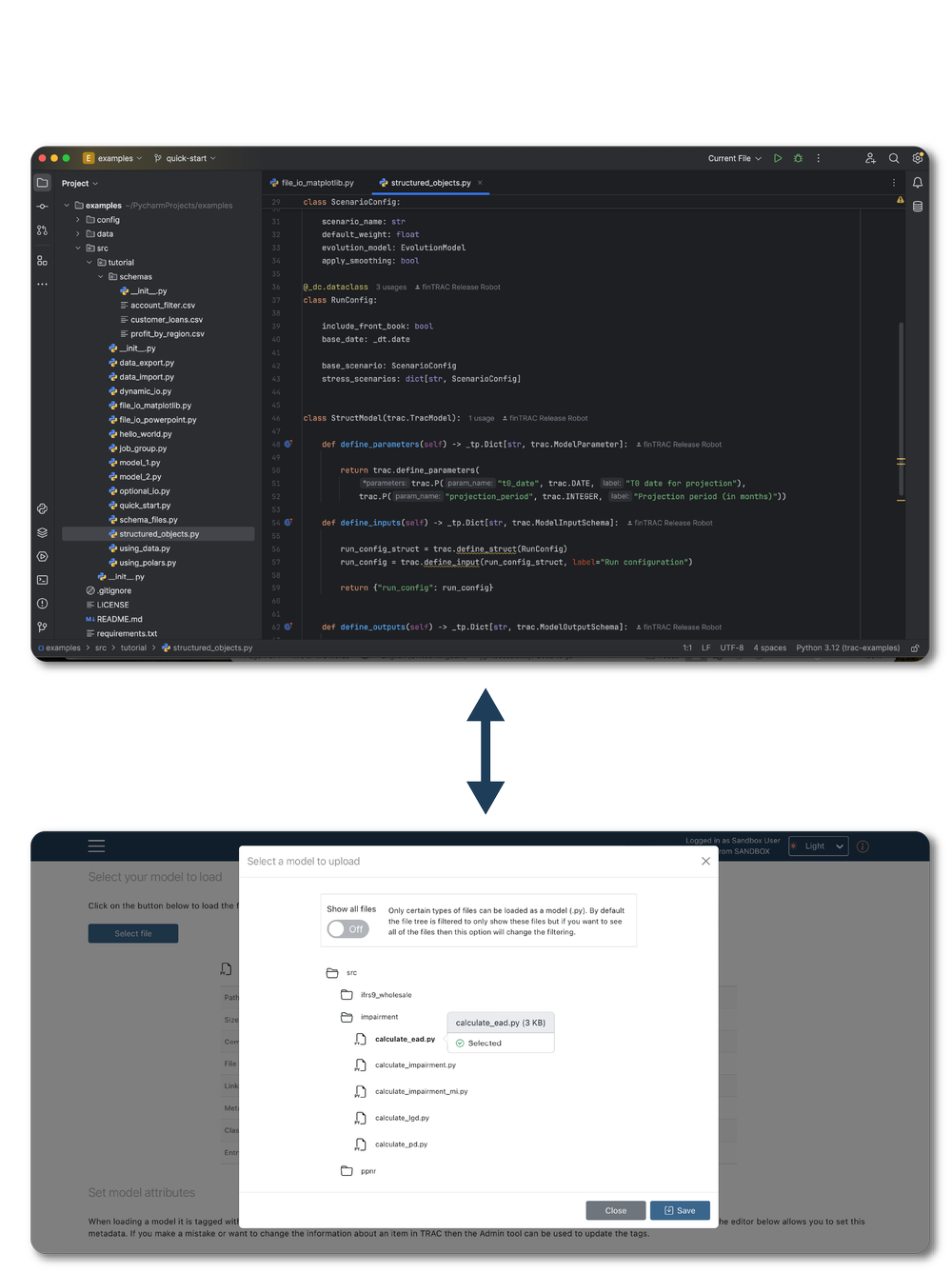
2. IMPORT MODELS
Models are uploaded from a repository. This creates trac’s internal representation of the model and makes it immediately available for use, for standalone execution or to build a Flow.
3. BUILD FLOWS
A Flow is the blueprint of a complex calculation involving multiple models that trac can run on demand. They are built on the platform with the FlowBuilder tool.
4. RUN JOBS
A calculation trac orchestrates using either a Flow or a Model as the basis. Each time trac fetches the data and code from storage at runtime.

THE BENEFITS OF VIRTUAL DEPLOYMENTS
Frictionless route-to-live, easy re-use of models and data across processes, and the trac guarantee.
No-Code Route-to-Live
With smart validations at each step of the journey, models can be safely imported from the IDE to production in a few minutes, with zero risk, zero coding and no platform-level interventions.
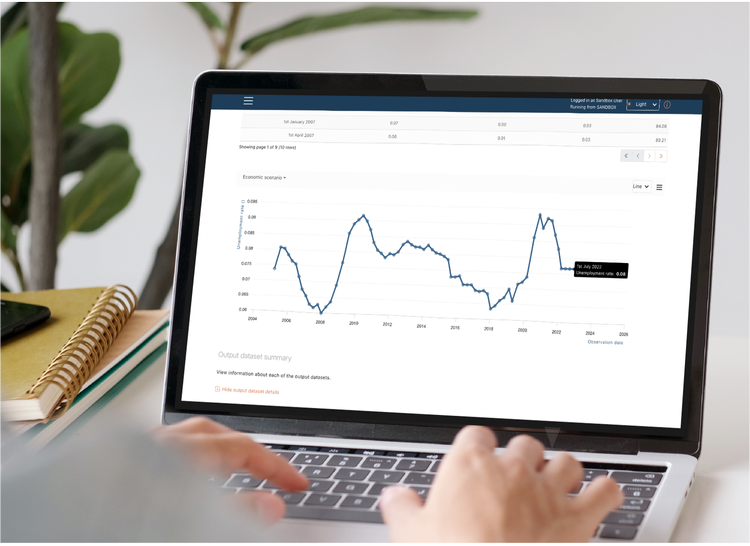

The Trac Guarante
Virtual Deployments are central to the platform's unique control architecture, which eliminates change risk and ensures that every calculation run on the platform is fully auditable and can be repeated with just a few clicks.
EXPLORE THE GUARANTEEExperimental Model Runs
With trac you are no longer restricted to having just one in-governance version of a model in production. Convert all your analytics into Flows and run them against production data and infrastructure to get rid of those clunky EUCs.
EXPLORE ANALYTICS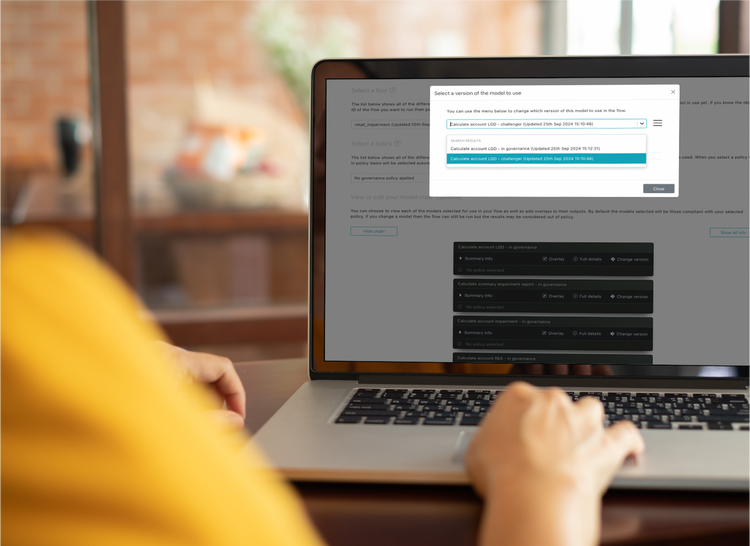
NO-CODE ROUTE-TO-LIVE
Models are incrementally validated by the platform, eliminating the need for re-coding.
LOCAL RUNTIME (OPTIONAL)
Does the code execute in the IDE using the trac runtime (Python) package and local data inputs? If so, it will pass the next step.
SCHEMA PRESENCE
Does the code contain a properly constructed function which declares its schema to the platform?
SCHEMA COMPATIBILITY
Does the proposed placing of a model in the Flow enable the input requirements defined in the schema, to be satisfied?
SCHEMA CONFORMITY
Does the code perform in line with the declared schema when executed using the trac runtime service?
Model Schemas
Mmodels in trac are self-describing — the executable code is wrapped inside a function which declares the schema to the platform. A model schema is simply the set of schemas which fully describe:
Visit our documentation site to explore the model API and learn how build self-describing models or 'wrap' existing code for deployment.
Self-Generating UI
The user-interface builds itself dynamically from the schemas of the models you select — once imported, a model is immediately available to: