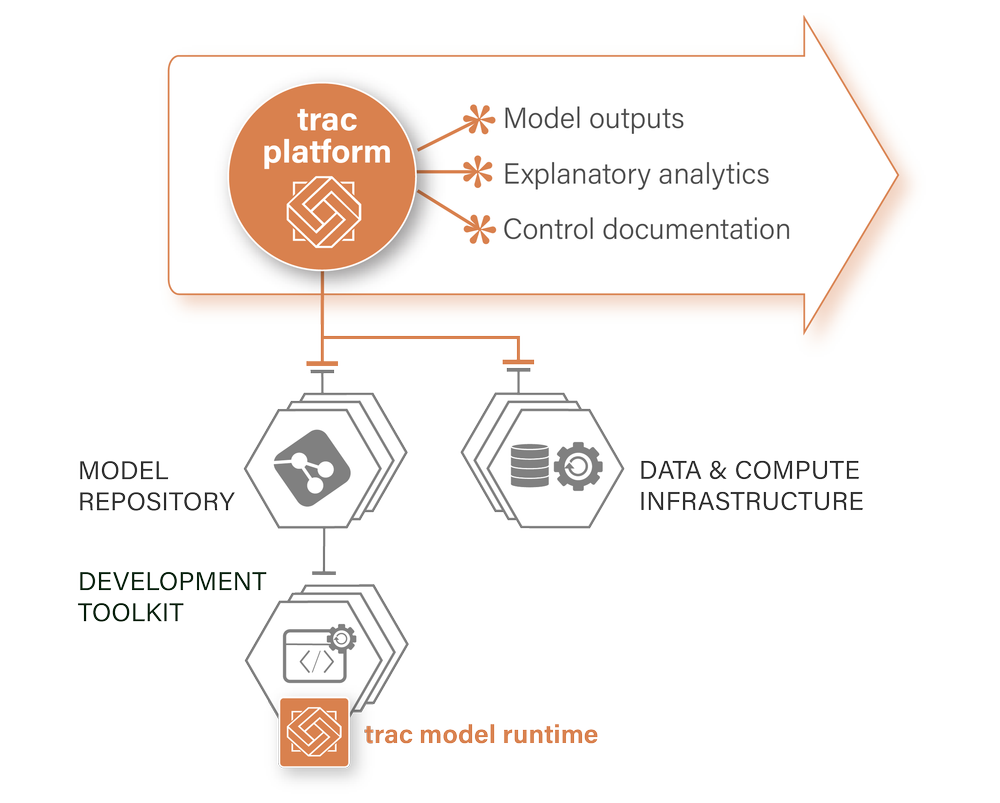
A thin orchestration layer
Extending your data science infrastrucure
The trac ecosystem
Sitting on top of your data and compute infrastructure use trac to:
- Curate models and data
- Orchestrate workflows
- Run models and calculations
Integrating with your business tools allows trac to manage:
- Deployment controls
- Libraries and environments
- Versioning & lineage
- Fine-grained permissions
The first of its kind
Self-describing, self-documenting and stateful
Self-describing
Built around a semantic data model that catalogues and describes every asset, process and calculation.
Self-documenting
Time-consistent recording of every change and action, building a complete version history of the whole platform.

Stateful
REvery version of every asset and every prior state of the whole plartform is available to each user, all the time.
Deployment options
Desktop, cloud, on-premises
A single-user sandbox deployment with all the platform’s core features. Ideal for exploration or to replace complex EUCs.
Free for community use.
Available on AWS, Azure and GCP we offer a simple marketplace solution and a scalable Kubernetes pattern, ideal for production workloads.
Simple scalable, cost-effective.
Various on-premises deployment patterns can also be supported depending on your infrastructure availability and needs.
Custom deployments welcome.

Our philosophy
Built on open-source foundations
We publish trac's core analytic services as an open-source project (TRAC D.A.P.) via FINOS — the leading advocate of open-source technology in financial services. The trac model runtime is also available to download from pypi.org.
Built for self-service
Democratising model use
The controlled route to live and trac’s unique guarantee empowers model owners and model users to self-serve in a safe environment, free of change risk — infrastructure teams don't need to be a bottleneck for deploying and managing business assets.
Explore user personas