Modern ModelOps
Integrating and extending your tools and infrastrucure
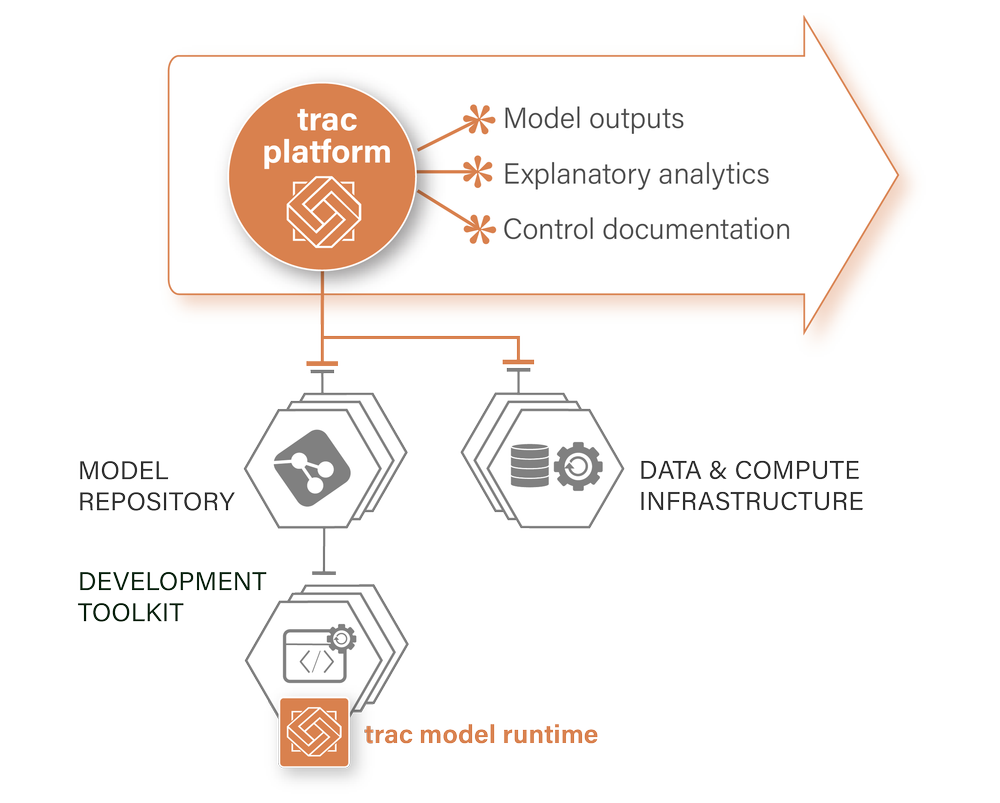
A thin orchestration layer that creates a self-describing, self-documenting and stateful analytics environment.
Platform attributes
Self-describing
Built around a semantic data model that catalogues and describes every asset, process, and calculation.

Self-documenting
Time-consistent action and update recording — a complete version history of the whole platform.

Stateful
Every version of every asset and every prior state of the platform is available to each user, all the time.
Production deployment
Flexible integration options
Integrating seamlessly with most modern data technologies, code repositories and development tools.
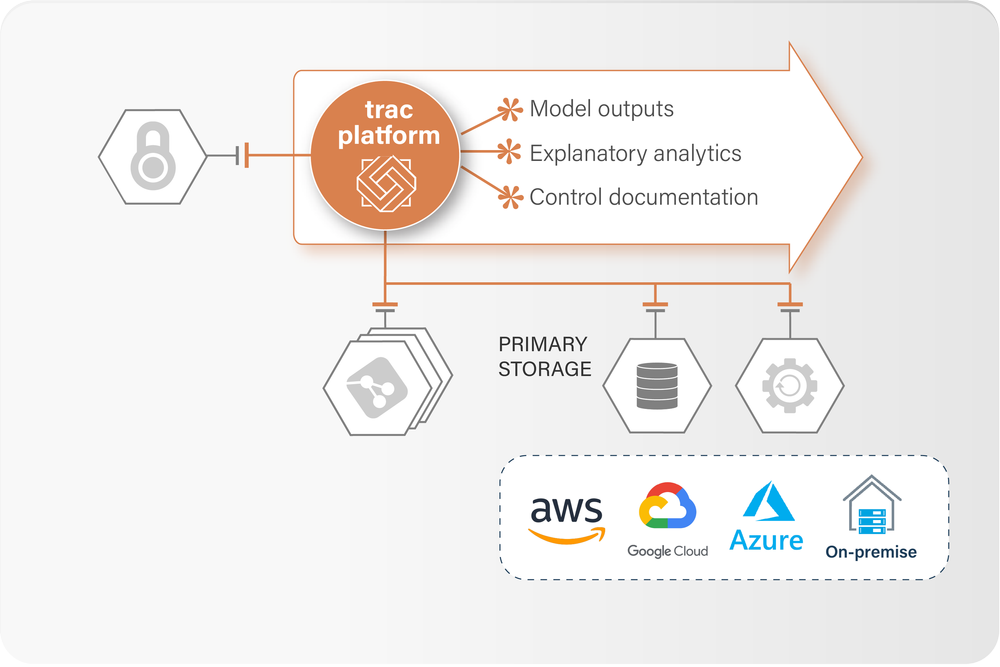
An append only data model ensures job repeatability. For cloud deployments, primary storgage uses regular bucketd (S3, GCS or Azure Blob).
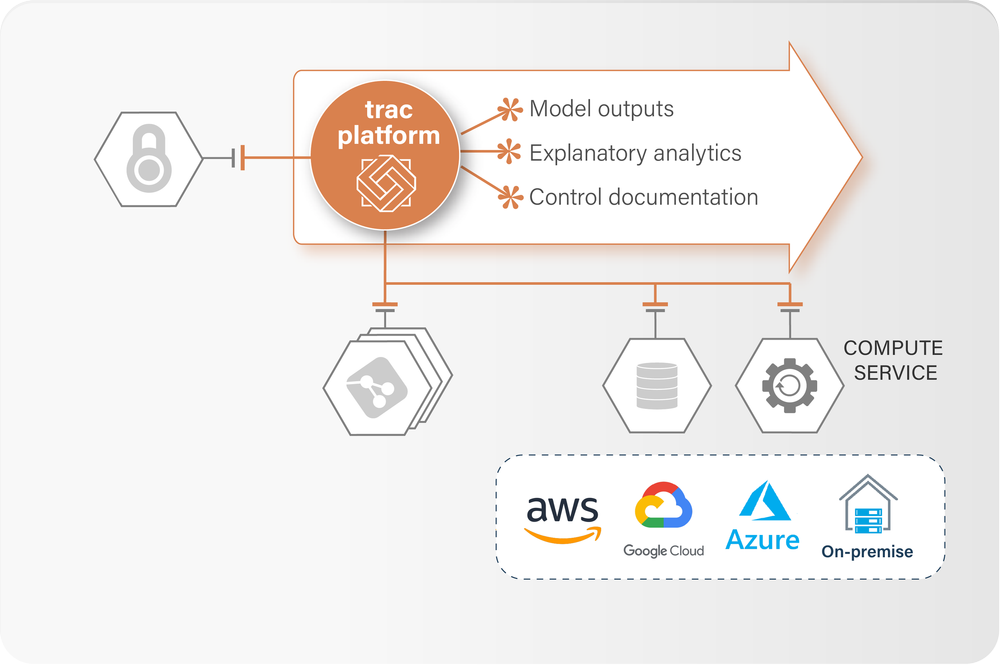
Kubernetes with single-node and distributed (Spark) for cloud deployments - other compute services are available for on-premises.
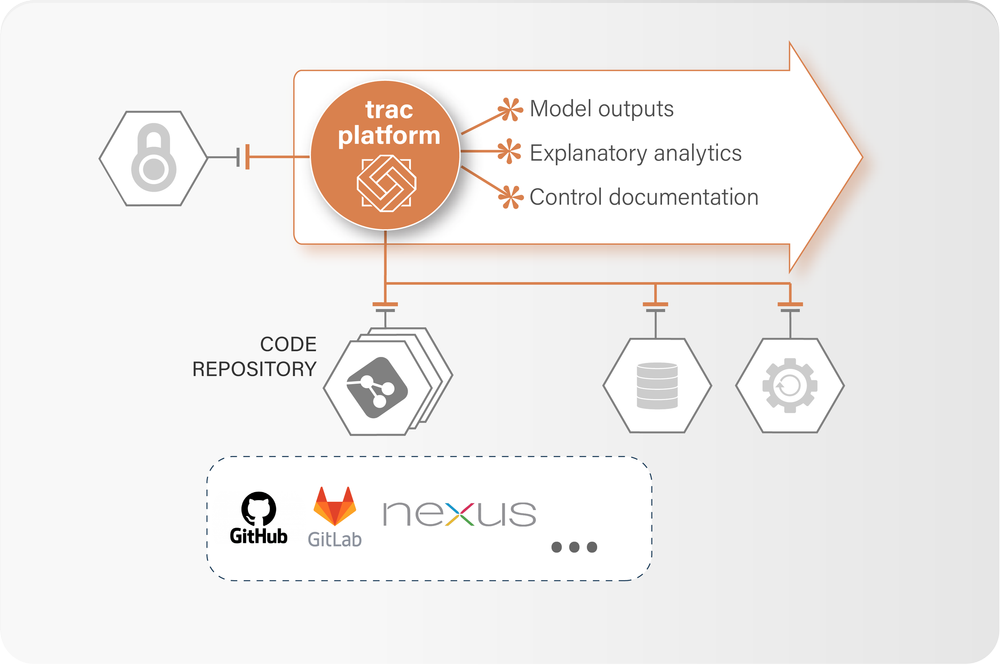
Models are stored in a repository and accessed dynamically at runtime. Git and Nexus are supported natively, custom repositories are accommodated with plug-ins.
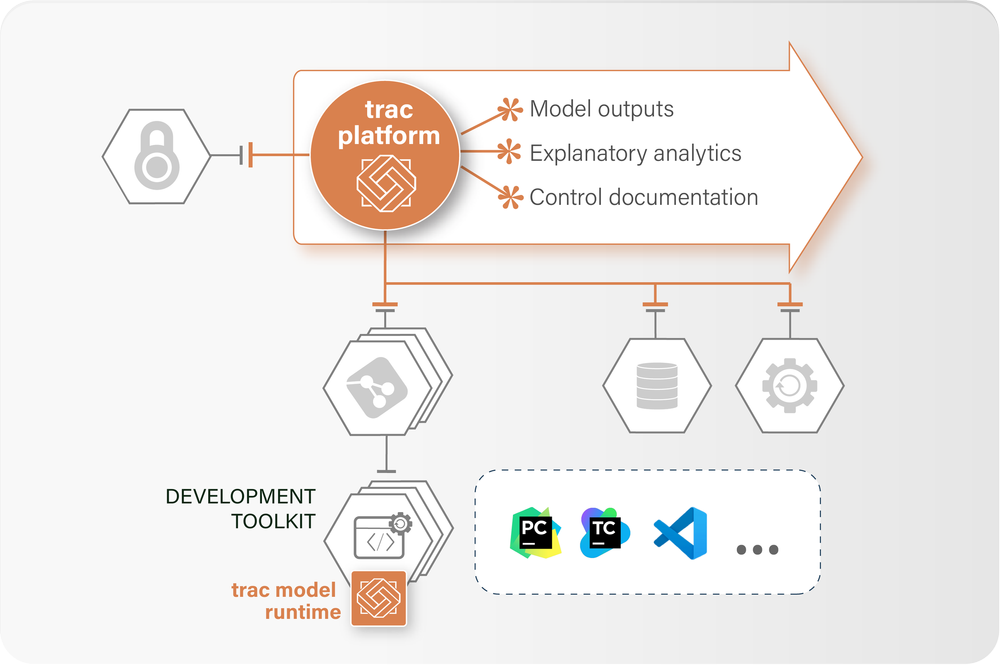
Deploy the trac runtime (python) to your IDE and build models that can be deployed to production with no code modification.
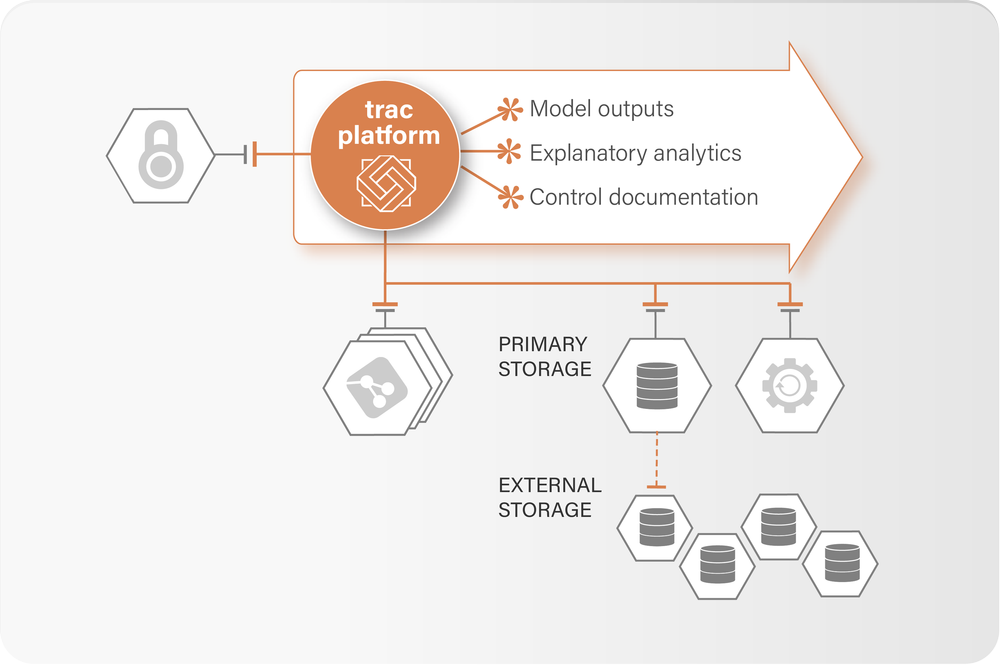
Connectivity is available for most common technologies including; object storage, file-like locations, databases, and SQL-like locations.
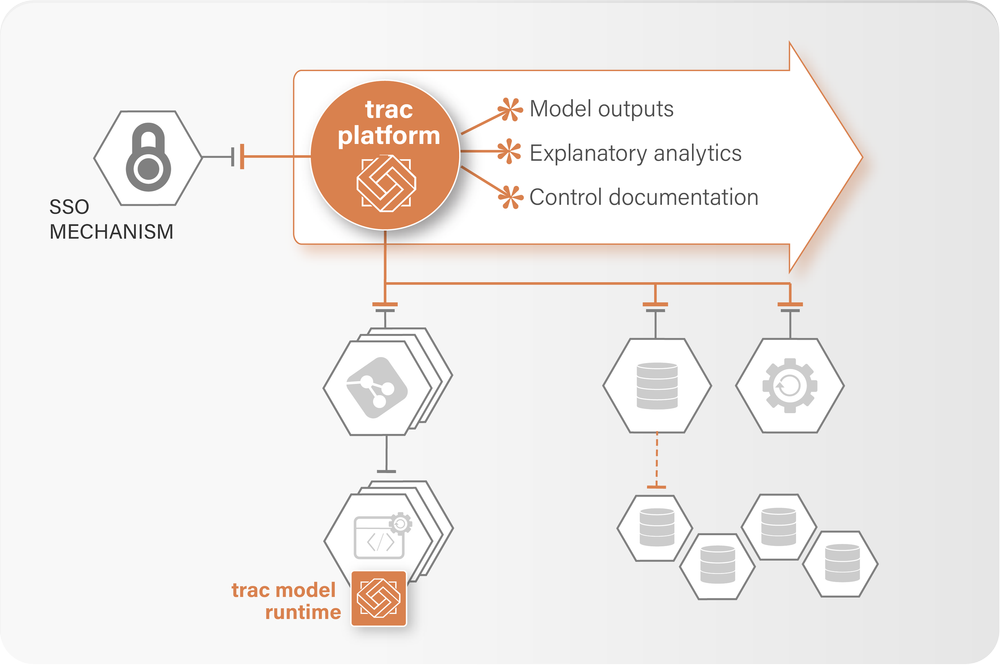
Plug into your SSO mechanism (Azue AD, SAML or OpenID) with roles assigned in the AD and fine-grain permissions configured in trac.

Our philosophy
Built on open-source foundations
We publish trac's core analytic services as an open-source project (TRAC D.A.P.) via FINOS. The trac model runtime is also available to download from pypi.org.
Explore open-sourceUniversal pattern
Development, desktop, or production system
Use trac in your IDE, as a desktop tool, or to run multiple production workdloads in the cloud or on-premises.